The Case for Dynamic Equivalence Alignments
#translation
(A Dynamic Equivalence Alignment is something like “Essentially Aligned Bible Translations”)
Token to token mapping is problematic, despite its ubiquity. It is theoretically the same as character to character mapping (a token is, with some exceptions, a set of characters delimited by whitespace). There is a fundamental distinction between structural units like characters, tokens, phrases, clusters, wordings, sets, etc., where the defining characteristic is composition (“what is this thing built out of?”) and semantic or functional units like entities, processes, predications, speech acts, definitions, scenarios, etc., where the defining characteristic is role or function (“what does this thing do in its immediate context?”).
With regard to alignment, the question driving any alignment is “what does span A have in common with span B?
The answer depends on what type of spans you are trying to align.
| Span type | Span A is… | Span B is… | Both spans have in common… | What type of similarity is this? | Does ER++ gold standard alignment data get it right? | Does the SOTA algorithm get it right? |
|---|---|---|---|---|---|---|
| Character | κ | a | Nothing obvious | Superficial | n/a | n/a |
| ω | o | Some kind of non-meaningful phonological similarity | n/a | n/a | ||
| Token | καὶ | as | Nothing obvious. | Depends on the type of token. | no | no |
| ὁ | the | Grammatical (sort of) and semantic | no | yes | ||
| ἔπεσεν | fell | Grammatical (partial) and analogous lexical semantics | yes | yes | ||
| Formal Syntactic Structure | καὶ ἐγένετο… (clause) | as he was… (adverbial phrase) | Partial lexical, partial grammatical | Depends on how similar the two languages’ grammatical systems are. | no | no |
| ἐν τῷ σπείρειν (prep. phrase) | scattering (part of compound verb ‘was scattering’) | no | yes | |||
| Semantic unit | ἐγένετο (event) | he was (event) | Semantic category | A meaningful semantic unit | no | no |
| ἐν ταῖς πορείαις αὐτοῦ (circumstance) | in the midst of his pursuits (circumstance) | Semantic category | n/a | n/a |
The case against token mapping as a basic strategy
Let’s assume that tokens are whitespace delimited, though this is not a necessary condition for the argument I want to make here. My argument is this: we should attempt to map semantic or meaning-based similarity instead of formal or structural similarity, because semantic overlap is implied by a translation, while formal overlap is explicitly repudiated (otherwise no translation would be necessary, or the task would be simple deciphering, as in an interlinear).
The issue with trying to map tokens between texts of different languages and/or translation styles (even within the same language) is based on the fact that a “token” is a formal category, and there is no principled linguistic or theoretical reason to assume that a token in language 1 will correspond isomorphically to a token in language 2. This is related to the use of whitespace to delimit tokens, but any tokenization strategy could fall prey to the same problem. Conversely, using whitespace delimited tokens is in fact a possible path forward, but the crucial hurdle to overcome is that we must not think of our task as one of aligning formal structures.
Consider the very nature of translation as a human activity. When one translates from text A to text B, the task is not to create a more-or-less graphically isomorphic re-presentation of text A in text B. The success of the task does not require there to be any structural or formal isomorphism between the two texts. Consider the following “translation” of John 3:16 into English (The Message), Chinese (CSB), and Arabic (KSS):
Source: For God so loved the world that he gave his only begotten son, that whoever believes in him should not perish but have everlasting life.
Target 1: This is how much God loved the world: He gave his Son, his one and only Son. And this is why: so that no one need be destroyed; by believing in him, anyone can have a whole and lasting life.
Target 2: 因为上帝爱世人,甚至将祂独一的儿子赐给他们,叫一切信祂的人不致灭亡,反得永生。
Target 3:لەبەر ئەوەی خودا ئەوەندە جیهانی خۆشویست، تەنانەت کوڕە تاقانەکەی بەختکرد، تاکو هەرکەسێک باوەڕی پێ بهێنێت لەناو نەچێت، بەڵکو ژیانی هەتاهەتایی هەبێت،
What is the one thing that none of these translations have in common? Structural isomorphism. There are degrees of formal similarity between them (somewhat similar overall length? Perhaps there are some similar phonological patterns (though I can’t tell, not knowing all the scripts). There are more formal similarities between the English versions, but this is, I would argue, only superficial. The reason these are translations (or perhaps we prefer the term paraphrase for same-language translation) is because they have semantic overlap.

Once we move to separate scripts, I hope it becomes clear that it is not a useful question to ask “Where does the word ‘God’ in the source appear in each of these target texts?” The word “God” does not appear in the other texts—that’s the whole point of translation. What we should be asking is something like “Where does the entity construed via the word ‘God’ get construed in the other texts?” This is a subtle difference, but it’s the difference between being able to answer the question and being stuck trying to accomplish a task that we are not well equipped to do in a scalable and reliable manner, and for which we have no formal evaluation apparatus.
When it comes to aligning whitespace-delimited tokens, just because it’s the state of the art, does not mean it is reliable or scalable, and it doesn’t mean we can’t do better with tools we already have.
Our gold standard data is not as reliable as we would like it to be. In addition, Clear Engine’s alignment relies on token-to-token alignment, and it is far from reliable out of the box. Even when improved by structure-based segmentation of units, the structures that each language uses to realize its semantics are always divergent to some degree.
Proposed path forward
The most basic implementation of semantics-based alignment for our purposes could take three forms (and these could also be combined into a single approach).
I think we should really pursue Option 3, since it best accords with the broader theoretical conception of translation, and it is likely to be even more useful than a word-level alignment in terms of the kinds of resources that can be retrieved.
Option 1: drop function words (pretty easy)
First, we can pursue the essentially aligned Bible translations approach. Initially this might mean we simply drop the so-called function words from the source language, and attempt to identify matching content words in the target languages. The downside of this coarse approach (i.e., simply dropping words we suspect will not be important), is that there are many likely exceptions. For example, a single Greek verb ἦλθον would align best with two English words “was going.”
Option 2: replace source text words with glosses or lemmas (easiest?)
Second, we could use language-specific glosses for aligning to another language. We have English and Mandarin glosses for our Greek and/or Hebrew texts, and I suspect we can much more easily align and automate evaluation for the alignments between an ‘interlinearized’ English string. For example,
-
Greek: καὶ εἶπεν αὐτοῖς Ποῖα;οἱ δὲ εἶπαν αὐτῷ Τὰ περὶ Ἰησοῦ τοῦ Ναζαρηνοῦ,
-
English glosses: And He said to them What things; - And they said to Him The things concerning Jesus of Nazareth,
The English glosses in the above example are probably more straightforward to align to English translations. These glosses can then be decoded back into the Greek text from which they were generated.
Option 3: treat alignments as annotations (best)
Third, and more ideally, we would think about alignments as what they really are, just another form of annotation, where text A is “annotated” with text B.
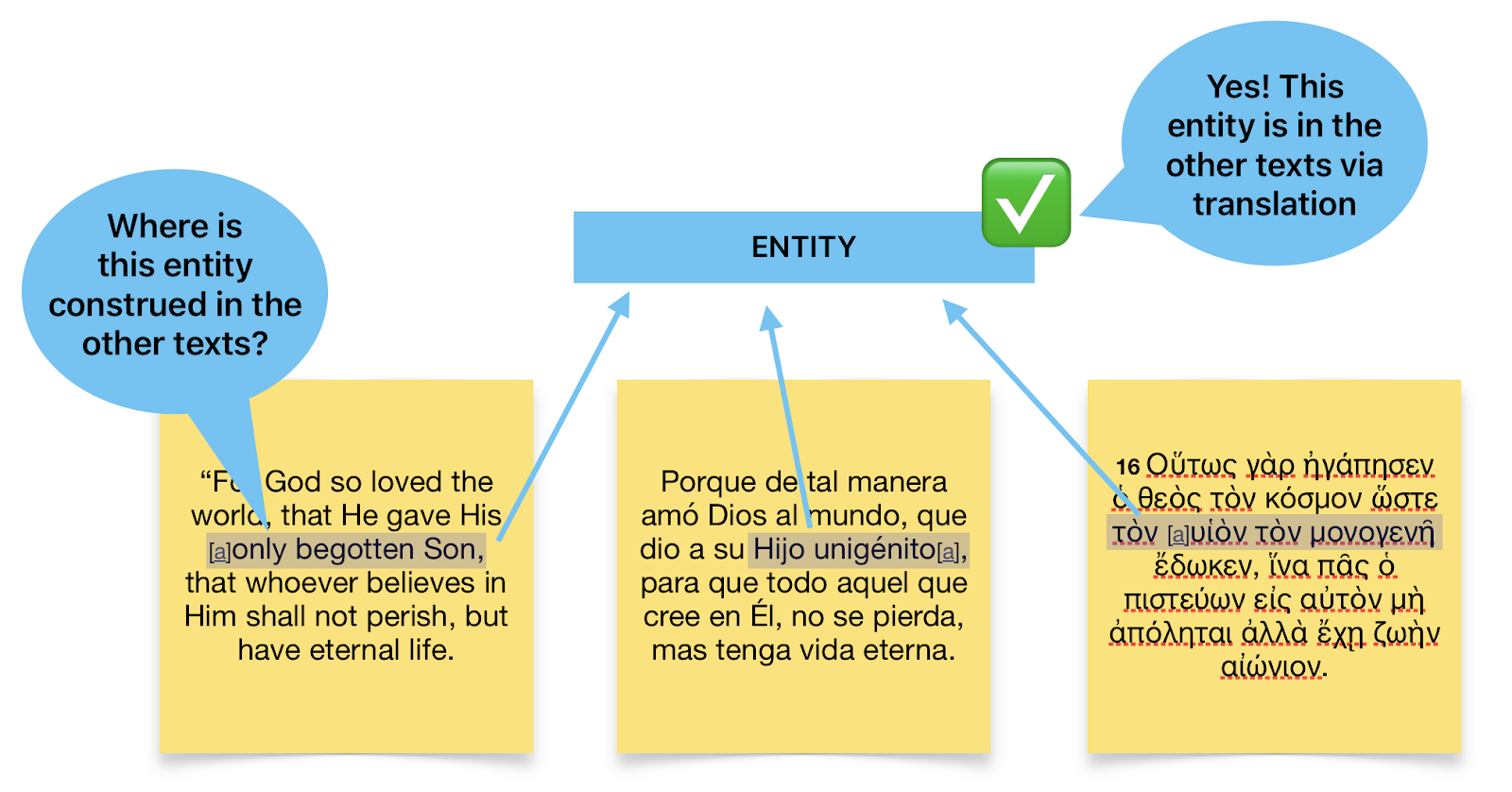
As the figure above illustrates, an annotation like “a semantic unit representing an entity” can be annotated across languages. It does not assume that the tokens in any language correspond isomorphically to tokens in another language, yet token- and character-level alignment is implicated by semantic alignment! I believe this is the best approach to alignment of the options listed above.
This approach can be technically implemented by indexing the spans in each text that should be annotated with each semantic annotation. This means we do not need to even use IDs for alignment—alignment can be a character-level annotation — because the things being aligned (e.g., the blue rectangular box in the figure above) are not tokens.
Summary
Let us make it our explicit goal to align meanings, not forms. The meanings are realized in forms, but the nature of the question changes because we are mapping form->meaning->form (which can be more or less objectively evaluated) instead of form->form (which implies the meaning without making it explicit).
Our goal should not be to align: FORM → FORM
Our goal should be to align:
FORM → MEANING → FORM
| Approach | Alignment task | Implementation |
| Formal or structural | FORM → FORM e.g., character → character token → token whitespace break → whitespace break | Language-specific tokenization. Every text must be parsed into individual forms that are as similar as possible to our Greek tokens to try to compare apples to apples - Greek is whitespace tokenized (+/- punctuation) - Hebrew is broken down to subword levels to try to match the Greek - Chinese? Arabic? Malayalam? |
| Semantic or functional | FORM → MEANING → FORM e.g., index → entity → index index → process → index index → circumstance → index index → speech act (e.g., statement | command | question | request) → index | Meaning is linked to string index ranges in any text we want to align - We identify meanings in the source text (or fall back to phrase structures if we do not have meanings, e.g., for Hebrew) - Meanings are indexed to arbitrary character spans in the source text file (e.g., Mike and Ben’s suggested implementation) - Meanings can be subsequently indexed to arbitrary strings in any text. This means that form-to-form mapping is implied by form-to-meaning-to-form, without the problematic aspects of trying to create a dataset that shows where Greek tokens appear in English texts, etc. |