Bridging the Gap Between Languages: A New Approach
The basic philosophy behind translating between languages is finding a way to bridge the gap.
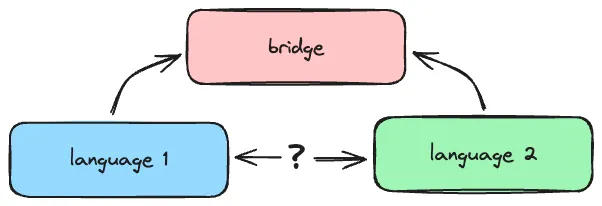
The Established Approach: Understanding and Expert Validation
The established approach has been to use an abstract notion of “understanding” as that bridge.
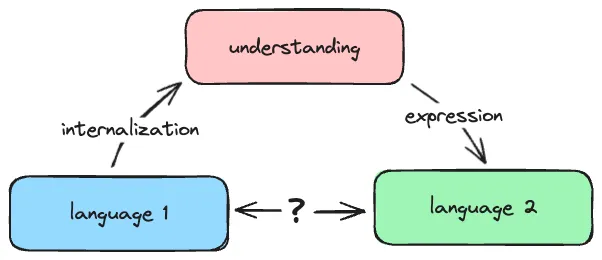
Under this paradigm, we start with Language 1, internalize and comprehend it to arrive at an “understanding”, and then express that understanding in Language 2. However, validating this approach is challenging, because the interim step of “understanding” does not exist as concrete, discrete units. As a consequence, the approach is not easily scalable, and the internalization process is protracted in an attempt to assure the validity of the “understanding”.
Validity, in turn, is assessed by experts in the target language, the subject matter, and by authorities and gatekeepers from within or without the respective communities.
The New Approach: Multimodal Assets and Consensus Validation
An alternative approach that is easier to validate and scale leverages multimodal assets like images, audio, text, animations, videos, and simulations to serve as the bridge between languages.
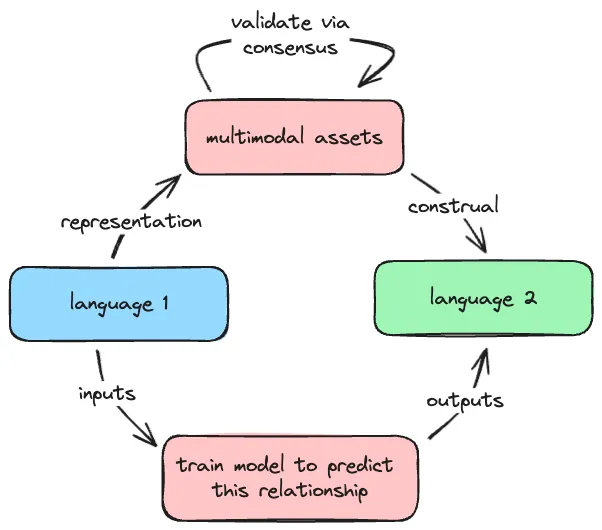
With this method, Language 1 is represented as a set of multimodal assets. Then Language 2 is generated by interpreting and describing those assets. Validation becomes straightforward, because the mapping between each multimodal asset and its linguistic representation in Language 2 is distinct and unambiguous.
The validation process is simple and proven - present a user with a snippet of Language 2, and ask them to match it to the correct multimodal asset, similar to how a Captcha test works. This allows the approach to be easily scaled without extensive software training.
Once we have established a robust set of validated asset-language pairings for the new language, we can strategically select a subset of the corpus that will provide sufficient data to train a small language model or fine-tune a large language model. As Zhou (2023) demonstrated, a model can be trained to translate the Bible with 90% accuracy using only 3% of the Bible as training data. This suggests that eliciting translations for a carefully chosen subset of a corpus via multimodal assets and Captcha-like validation is feasible.
The key advantage of this approach is that it does not require any prior knowledge of the target language, making it massively scalable for translating low-resource languages that have been historically difficult to support. By focusing data collection efforts on the most information-dense portions of a corpus, we can efficiently gather the necessary training data to enable high-quality machine translation for the long tail of languages.
In summary, using multimodal representations as a bridge between languages offers a promising alternative to the “understanding” based approach that is easier to robustly validate and scale. Combined with strategic subsampling of corpora for data collection, this paradigm shift could dramatically expand our ability to develop machine translation capabilities for low-resource languages.
Reference:
Zhou, Z. (2023). [TBA].